
In this blog post I demonstrate how to map statistically significant differences between (groups of) texts. For this I contrast the different emphasis in the Russian and English language Wikipedia pages about the Russian protests of 2011

Visualising textual data is complicated. Simple efforts, created by Wordle or similar, are not great. Partly this is, as Drew Conway pointed out, because they use space and colour in a meaningless way; only the size of the word says anything about its significance. Conway attempted to improve the word cloud by plotting words on an axis - words more associated with Sarah Palin to the left, words more associated with Barack Obama on the right.
{kind=link}
I think this is an excellent idea, but my main gripe with the approach is that it's not especially robust statistically. So below I present a way to compare any two texts or groups of text, and then visualise statistically significant differences between them.
Below I outline how to load and process two texts or corpuses and to graph qualitative differences between the two sets. All going well, we should end up with an image something like that on the left
Getting the data
First we need to conduct a keyword analysis by identifying words or word pairings disproportionately present in the text.
To do this I first loaded the texts into R. Make sure to set R to the appropriate locale! This will save you a lot of trouble if dealing with almost any language except English. I chose to include a stop list, that is a list of words to be excluded from the analysis. I excluded common words such as prepositions, personal pronouns, some adjectives etc. For a full list see (here)[]. Removing these words greatly reduces the number of terms in the data, and also reduces the degree to which the common words obscure less common terms.
# required libraries If using foreign languages, Set the locale to
# 'Russian' Sys.setlocale('LC_CTYPE','russian')
# get some data. E.g. the English language wikipedia page about Russia,
# and the Google translate version of the Russian language page:
txt1 <- readLines("http://pastebay.net/pastebay.php?dl=1182135", warn = F)
txt2 <- readLines("http://pastebay.net/pastebay.php?dl=1182136", warn = F)
# Alternatively, get the bible, split into old and new testaments: txt <-
# readLines('http://www.gutenberg.org/cache/epub/10/pg10.txt') a <-
# grep('The Gospel According to Saint Matthew',txt,ignore.case=T) txt1 <-
# txt[1:a] txt2 <- txt[a:length(txt)]
# Or load locally stored files(s) into R. This latter method allows you to
# specify a directory source, meaning a large number of texts can be
# loaded txt1<-readLines('myfile.txt') txt2<-readLines('myfile2.txt')
# Load a custom stoplist (optional)
# stopList<-readLines('d:/temp/listStemmed.txt')
# stopList<-tolower(stopList) stopList<-data.frame(stopList)
Processing the data
To process the texts I used the tm package. Before analysing the texts I removed duplicated lines, as might be caused for instance by titles being printed twice. When counting words every unique term is identified, thus 'Victory', 'victory', and 'victory!' are considered unique terms. To avoid this I converted the texts to lower case, removed punctuation. Additionally, because Russian is an inflectional language, I used the Snowball stemmer to stem the documents. This has the positive effect of treating 'succeeded' and 'succeeds' equally, but the unwanted effect of also merging distinct terms such as 'Victor', 'Victoria', and 'Victory'. Numbers are also removed at this stage
# remove duplicated lines
require(tm)
library(stringr)
txt2 <- unique(txt2)
txt1 <- unique(txt1)
# remove punctuation. Note: tm has a tool for this, but it doesn’t work
# with Russian, as it identifies some Cyrillic characters as punctuation
# rather than letters.
txt1 <- str_replace_all(txt1, "\\.|\\?|\\:|\\;|\\!|\\,|\\\"|\\-",
" ")
txt2 <- str_replace_all(txt2, "\\.|\\?|\\:|\\;|\\!|\\,|\\\"|\\-",
" ")
txt2 <- Corpus(VectorSource(txt2), pos = .GlobalEnv)
txt1 <- Corpus(VectorSource(txt1), pos = .GlobalEnv)
# remove white space, convert to lower case, and stem the document This
# may take some time. Experiment with a small sample and tweak code before
# attempting to process large data!
txt1 <- tm_map(txt1, stripWhitespace)
txt1 <- tm_map(txt1, tolower)
txt1 <- tm_map(txt1, stemDocument, language = "english")
txt1 <- tm_map(txt1, removeWords, stopwords("english")) #or: stopwords(stopList) #if using custom list
txt1 <- tm_map(txt1, removeNumbers)
txt2 <- tm_map(txt2, stripWhitespace)
txt2 <- tm_map(txt2, tolower)
txt2 <- tm_map(txt2, stemDocument, language = "english")
txt2 <- tm_map(txt2, removeWords, stopwords("english"))
txt2 <- tm_map(txt2, removeNumbers)
After the documents had been processed they were loaded into a document term matrix. The matrix presents the number of times each unique term features in each distinct document. Then add all the documents together to get aggregate scores. Finally, any missing values are removed, and the data is converted to a data frame:
dtmOne <- (DocumentTermMatrix(txt1))
dtmTwo <- (DocumentTermMatrix(txt2))
dtmOne2 <- data.frame(as.matrix(dtmOne))
dtmTwo2 <- data.frame(as.matrix(dtmTwo))
v1 <- as.matrix(sort(sapply(dtmOne2, "sum"), decreasing = TRUE)[1:length(dtmOne2)],
colnames = count)
v2 <- as.matrix(sort(sapply(dtmTwo2, "sum"), decreasing = TRUE)[1:length(dtmOne2)],
colnames = count)
v2 <- v2[complete.cases(v2), ]
v1 <- v1[complete.cases(v2), ]
wordsOne <- data.frame(v1)
wordsTwo <- data.frame(v2)
The tm package is slow and processor intensive (r is not well suited for textual analysis). When dealing with larger databases I have used the tm.plugin.dc package to create (distrubted corpora )[Author: Ingo Feinerer, Stefan Theussl], which keeps the data stored on the hard drive rather than in memory.
# When using a distributed corpus it helps if texts are pre-processed.
# This may be done in R using a loop, or more efficiently by command line
# using sed, awk, grep etc. (Cygwin is great for this). If analysing large
# databases, use the code below: require (tm.plugin.dc) pattern is
# optional. It allows only part of a directory's content to be selected,
# in this case all .txt files txt1 <-
# DistributedCorpus(DirSource('directory1',pattern='.txt')) txt2 <-
# DistributedCorpus(DirSource('directory1',pattern='.txt'))
# continue as above
If comparing only two texts the tm package may be bypassed altogether. The tm_map function above merely applies a function to a corpus, the functions within may be used independently, after which a keyword table may be created using table(). To use this method texts should first be split into a list of words:
# require(stringr) require(tm) txt1 <- tolower(txt1) txt1 <-
# stripWhitespace(txt1) txt1 <- str_replace_all(txt1,
# '\\.|\\?|\\:|\\;|\\!|\\,|\\'|\\-',' ') txt1 <-
# unlist(str_split(txt1, ' ')) #break text into individual words. Needed
# for stemming: txt1 <- stemDocument(txt1, language = 'russian') txt1 <-
# data.frame(table(txt1))
Now the data is formatted we can merge the two tables by row names, and remove any words found in the stoplist. For this to work the stoplist must also be stemmed!
wordsCompare <- merge(wordsOne, wordsTwo, by = "row.names", all = TRUE)
wordsCompare[is.na(wordsCompare)] <- 0
Calculating statistical significance
Next we calculate the relative number of mentions per term by calculating proportions. Now, one might wonder whether differences between texts are random, or whether there is some consistent difference. Clearly I am interested in the latter, so we use the proportions to calculate whether the observed differences between the two datasets are statistically significant using a z-test. We can now remove insignificant terms at our chosen confidence level. Normally this would be 95% which corresponds to a z-score of 1.96, but for the sake of this example we'll keep all the data. A two-proportion z-test is calculated using this formula
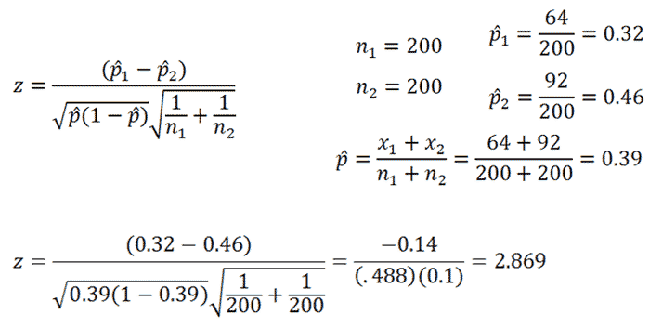{kind=link}
wordsCompare$prop <- wordsCompare$v1/sum(wordsCompare$v1)
wordsCompare$prop2 <- wordsCompare$v2/sum(wordsCompare$v2)
wordsCompare$z <- (wordsCompare$prop - wordsCompare$prop2)/((sqrt(((sum(wordsCompare$v1) *
wordsCompare$prop) + (sum(wordsCompare$v2) * wordsCompare$prop2))/(sum(wordsCompare$v1) +
sum(wordsCompare$v2)) * (1 - ((sum(wordsCompare$v1) * wordsCompare$prop) +
(sum(wordsCompare$v2) * wordsCompare$prop2))/(sum(wordsCompare$v1) + sum(wordsCompare$v2))))) *
(sqrt((sum(wordsCompare$v1) + sum(wordsCompare$v2))/(sum(wordsCompare$v1) *
sum(wordsCompare$v2))))) #z formula
# keep only data of at least moderate significance. Use (abs) to keep
# significant negative z-scores.
# wordsCompare<-subset(wordsCompare,abs(z)>1.96)
Presentation
Now for data visualisation. First let's inspect the data to check that everything looks OK, then lets calculate how different the two proportions are. Finally, let’s plot this, indicating which data points are statistically significant, as well as quantifying the degree of difference. This allows us to make a judgement on whether a difference is meaningful as well as statistically significant (statistical significance is the curse of large data. Or something):
wordsCompare <- wordsCompare[order(abs(wordsCompare$z), decreasing = T), ] #order according to significance
# calculate percentage reduction:
wordsCompare$dif1 <- -100 * (1 - wordsCompare$prop/wordsCompare$prop2)
# calculate percentage increase
wordsCompare$dif2 <- 100 * (1 - wordsCompare$prop2/wordsCompare$prop)
# merge results. Very clunky, must be better way:
wordsCompare$dif <- 0
wordsCompare$dif[wordsCompare$dif1 < 0] <- wordsCompare$dif1[wordsCompare$dif1 <
0]
wordsCompare$dif[wordsCompare$dif2 > 0] <- wordsCompare$dif2[wordsCompare$dif2 >
0]
wordsCompare$dif1 <- NULL
wordsCompare$dif2 <- NULL
require(ggplot2)
ggplot(wordsCompare, aes(z, dif)) + geom_point()

as we can see, there is a non-linear relationship between z score and higher percentage difference between the samples, due to the fact that many of the differences, large in relative terms, are very small in absolute terms. We can also see there are a number of points at 100%, meaning a word is present in one sample but not the other. These points may be interesting, but should probably be removed - one cannot really compare something to nothing. We can tidy up the plot by adding labels, limiting the number of points, add colour to indicate statistical significance, as well as axis labels. I've also flipped the axes and made the z-scores absolute:
require(ggplot2)
wordsCompare$z2 <- 1
wordsCompare$z2[abs(wordsCompare$z)>=1.96] <- 0
wordsCompare <- wordsCompare[wordsCompare$z>-99&wordsCompare$z<99,]
#exclude terms infitiely more or less used
wordsCompare <- wordsCompare[order(abs(wordsCompare$prop2+wordsCompare$prop),decreasing=T),]
ggplot(head(wordsCompare,50), #select number of points in plot
aes(dif,log(abs(v1+v2)),label=Row.names,size=(v1+v2),colour=z2))+ #plot z value against difference
geom_text(fontface=2,alpha=.8)+
scale_size(range = c(3, 12))+#specify scale
ylab("log number of mentions")+
xlab("percentage difference betwen samples\n <---------More on Russian language page ------|-----More on English language page-------->")+
geom_vline(x=0,colour="red",linetype=2)+theme_bw()+theme(legend.position="none")+
ggtitle("terms featuring differently in \n Russian and English language Wikipedia pages about Russia")

Some trends are immediately obvious: firstly, the English language is a lot more focused on the actual protests, on opposition activity, on demonstrations, etc. Bolotnaya and the white ribbon campaign feature, while Vladimir Putin and Navalny is a major actor.
The Russian language page focuses more on the numbers involved, people, the details of the election.
The graph also highlights how terms in the centre of the graph may be due to random differences. They are plotted in a different colour to highlight they have not met the 95% threshold and hence not statistically significant. They may nonetheless warrant closer inspection. This emphasises that for terms that feature only a few times to appear significant, they must feature very disproportionately in one sample. A larger sample, for instance a corpus of texts, would reveal many more significant terms.
To enhance the illustration above one might examine the results and identify terms that yield little meaning, add these to the stoplist, and re-run the script; this would reduce clutter and help emphasise significant differences.
Finally, we can also list terms that feature significantly more in one sample. Note how this must be treated with care; formatting differences will often appear significant. Note for instance the presence of roman numerals, Wikipedia terms such as 'edit', etc.
# print terms significantly overrepresented on the Russian language page:
wordsCompare$Row.names[wordsCompare$z < -1.95]
[1] "ralli" "polic" "opposit" "meet"
[5] "thousand" "action" "citi" "edit"
[9] "power" "million" "detain" "repres"
[13] "citizen" "duma" "note" "boulevard"
[17] "violat" "agre" "festiv" "pond"
[21] "central" "immedi" "process" "releas"
[25] "system" "prepar" "detent" "doe"
[29] "word" "camp" "clean" "wrote"
[33] "resolut" "banderlog" "becom" "caus"
[37] "chistoprudni" "morn" "walk" "complet"
[41] "connect" "kudrinskaya" "marsh" "nikitski"
[45] "promis"
# print terms significantly overrepresented on the English language page:
wordsCompare$Row.names[wordsCompare$z > 1.95]
[1] "protest" "squar" "demonstr" "report" "activist"
[6] "bolotnaya" "X...." "white" "journalist" "station"
[11] "claim" "politician" "X.edit." "vote" "former"
[16] "offici" "ribbon" "alexey" "union" "yabloko"
[21] "embassi" "soviet" "densiti" "fine" "manezhnaya"
[26] "origin" "permit" "protestor" "run" "sergey"
[31] "writer" "account" "chirikova" "fund" "luzhniki"
[36] "maximum" "novosti" "promin" "provid" "ria"
[41] "told" "twitter" "war" "whilst" "corrupt"
[46] "denounc" "element" "evid" "falsif" "mcfaul"
[51] "musician" "nashi" "organis" "record" "spoke"
[56] "third" "tweet" "visit" "vladivostok" "yavlinski"
[61] "yevgeniya"
Rolf, Do you have a paper/conference with this visualization approach that I can provide a reference for if I used the algorithm?
ReplyDeleteHi Vivek!
DeleteI;m glad you've found this useful! I cited it once, in a yet to be published article, but I referred to the blog entry. Sadly I never got around to doing a more formal writeup of the method. If you intend to use it (rather than just shooting it down in a footnote), one issue I've been struggling with, and have yet to find a satisfactory answer to, is the problem of numerous probability tests: the idea of a 95% confidence threshold goes out the window when we calculate scores for hundreds of observations (we would expect 1/20 false positives, anyway). So the formula will need to be adjusted in some way.
Hope this helps, best Rolf
thanks, this is great! do you have any suggestion for how to avoid having the words overlapping the plot? maybe some way to jitter them?
ReplyDeleteReally cool, thanks for sharing.
ReplyDeleteMy only question is whether you misstyped when you wrote
v2 <- as.matrix(sort(sapply(dtmTwo2, "sum"), decreasing = TRUE)[1:length(dtmOne2)],
colnames = count)
towards the beginning of the script. Did you mean to scale to the length of dtmTwo2 instead?